
Você já ouviu falar de web scraping? Essa é uma das técnicas de automação de marketing mais avançadas hoje em dia, tendo sido aperfeiçoada por vários anos mas 100% viabilizada agora, na era da IA.
O web scraping é um avanço tecnológico que já estamos esperando há anos. A tecnologia nos permite viralizar um post da noite para o dia, mas ao mesmo tempo, éramos limitados: não era possível armazenar as informações de quem interagia com a marca.
Por exemplo: se seu post teve 3.000 comentários dentro de uma semana, a forma convencional de armazenar as informações dos perfis que interagiram era acessar um por um e anotar, na mão, as informações relevantes.
É essa a revolução do web scraping. Subitamente, você não precisa mais disso. Mas por que? O que mudou? Como o web scraping funciona, e como colocá-lo em prática?
Vamos descobrir tudo isso agora. Acompanhe:
O que é o web scraping e por que ele se tornou popular agora?
Só deixando um ponto claro: o web scraping já existe desde que a internet passou a existir. Scripts que copiavam as informações de um site e as armazenavam em um banco de dados já eram realidade desde os anos 90.
Porém, a dificuldade estava principalmente em poder de processamento e acessibilidade. E claro: não existiam as redes sociais, local onde é mais interessante — e difícil — fazer web scraping.
Fazer o web scraping de uma página que seguia os padrões HTML e CSS na sua forma mais pura não era muito complicado.
As redes sociais que foram surgindo na virada do milênio, como o MySpace e o Orkut, eram constantemente alvos de web scraping por agências especializadas por conta disso.
Mas o surgimento de plataformas fechadas, como o Facebook e o Instagram, dificultou bastante esse processo.
Ao invés de HTML puro server-side, as novas redes sociais tinham como base principal o JavaScript no front-end, dificultando o scraping.
E não só isso: as plataformas eram acessíveis apenas via API, que não eram públicas, a maior parte do conteúdo era carregado client-side dentre outras dificuldades técnicas.
Para realizá-lo, seria necessário a criação de navegadores virtuais que imitassem o comportamento dos usuários.
É uma técnica quase de força bruta: os bots scrapers simulam o comportamento humano, realmente acessando os perfis, lendo e armazenando as informações. Só que em uma velocidade absurda advinda dos avanços em processamento, memória etc.
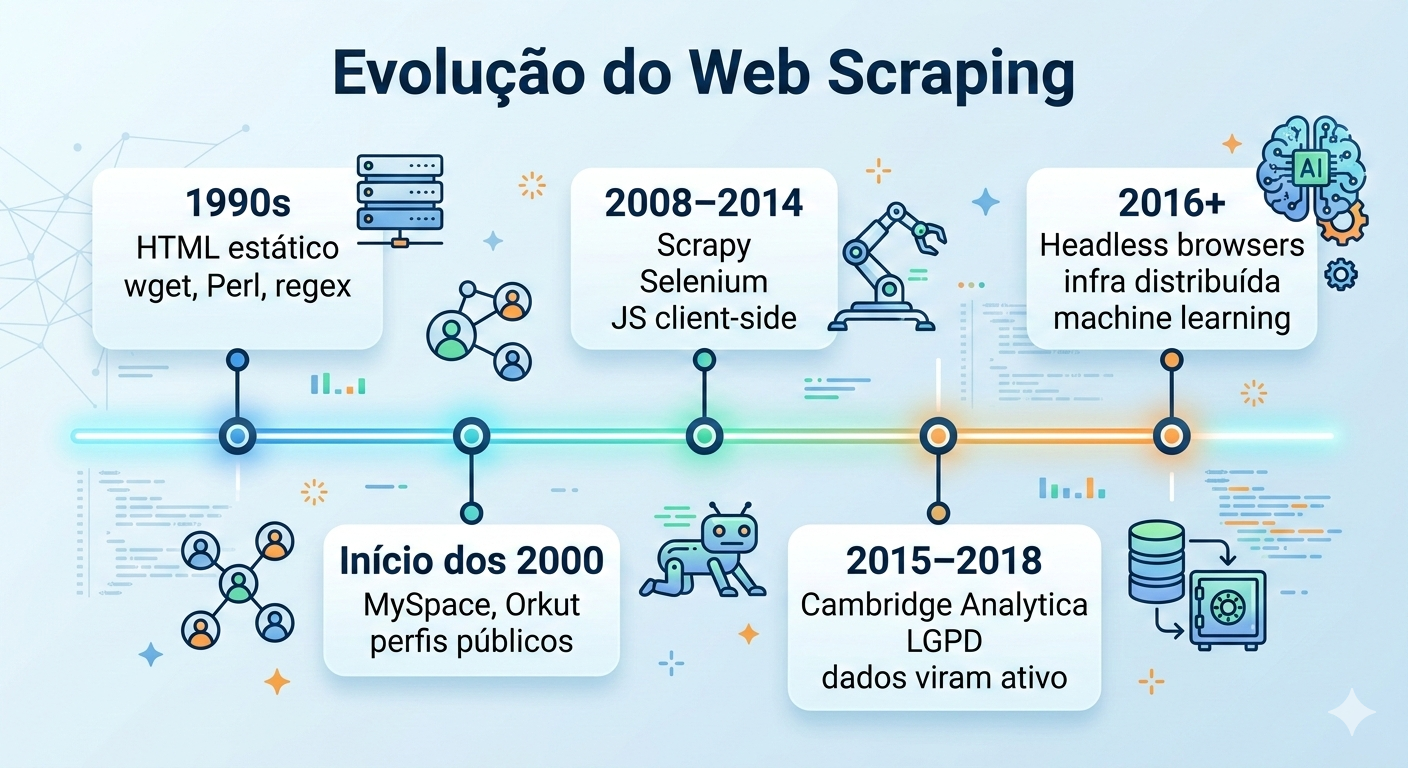
Veja logo abaixo uma rápida linha do tempo do web scraping ao longo das décadas. É bem breve e serve como curiosidade. Sinta-se livre para pular, caso queira ir direto para a sessão tutorial do texto:
Anos 1990 — A fase artesanal
Scraping nesse cenário era algo bem direto. Um programa fazia exatamente o mesmo pedido que um navegador faria: uma requisição HTTP.
Quando o servidor respondia, ele mandava o HTML da página.
O scraper então abria esse HTML e procurava as informações dentro dele, realizando o parse do markup — linguagem padrão do HTML — para texto.
E a partir desse texto, um sistema encontra e destaca as informações solicitadas.
Ferramentas e contexto:
- Surgimento do wget em 1996;
- Scripts em Perl e Python para parsing de HTML;
- Regex como solução dominante;
- Baixa proteção anti-bot;
Nessa época, o scraping era simples, mas limitado por infraestrutura, banda e baixo incentivo econômico — os dados ainda não importavam muito.
Início dos anos 2000 — Redes sociais abertas
Nessa época, plataformas como Myspace e Orkut cresceram rapidamente. As redes sociais estavam começando, mas seguiam os padrões de desenvolvimento web da época.
O cenário era o seguinte:
- HTML majoritariamente server-side;
- Perfis públicos acessíveis via URL direta;
- Pouca sofisticação em detecção automatizada;
Ou seja: pessoas estão criando perfis e distribuindo seus dados demográficos na internet. Nessa época, o Scraping passa a ser usado para marketing, pesquisa acadêmica e mineração de dados sociais.
Você pode até ler estudos acadêmicos da época baseados em scraping, como “Characterizing user navigation and interactions in online social networks”.
Mas esses dados ainda são limitados: objetivamente, não era possível saber muito sobre um público alvo a partir dos seus perfis.
É nesse momento, porém, que entendemos a validez de pesquisas qualitativas com base em “suposições” lógicas sobre uma amostra estatística bem grande.
Nos anos seguintes e até hoje, estamos melhorando a forma de pensar esses questionamentos.
2008–2014 — Profissionalização
Com a consolidação de plataformas como Facebook e LinkedIn, o cenário muda.
Há mudanças estruturais na própria internet, de certa forma. A economia de dados direciona o foco para as redes sociais — é mais valioso fazer scraping de perfis.
Porém, ao mesmo tempo, as redes sociais trazem diferenças:
- Adoção massiva de JavaScript e renderização client-side;
- Surgimento de frameworks como Scrapy;
- Automação de navegador com Selenium;
- Início de sistemas robustos de anti-bot;
O scraping passa a ser um projeto estruturado, com retorno e ROI.
2015–2018 — Conflito jurídico e dados como ativo estratégico
Dados passam a ser ativos centrais da economia digital, e considerados parte das plataformas, que querem decidir sobre o que fazer com eles.
E mais do que isso: a sociedade civil está alerta sobre dados disponibilizados na internet em geral.
Marcos relevantes:
- Caso hiQ Labs vs LinkedIn;
- Escândalo envolvendo Cambridge Analytica (não foi scraping clássico, foi captura de dados direta. Mas levou o debate adiante e propiciou o surgimento da LGPD no Brasil);
O trabalho aqui deixou de ser de bastidores. Ele passou a ser praticamente debate mundial, ganhando holofotes que, ao mesmo tempo, trouxeram avanços éticos e popularizaram a técnica de scraping.
É daqui pra frente que tudo muda.
Hoje — Industrialização e evasão sofisticada
Surge o uso massivo de infraestrutura distribuída e headless browsers como Puppeteer e Playwright.
Características da fase atual:
- Execução paralela em múltiplas regiões;
- Rotação inteligente de IP e fingerprinting;
- Simulação de comportamento humano;
- Integração com pipelines de machine learning.
Tipos de scraping e o que você pode aplicar agora

Vimos então que a evolução do web scraping nos deixou com vários legados. Não podemos ignorar a tecnologia e os métodos do passado em detrimento do que há de novo hoje.
Na verdade, tudo se acumula. O scrapings mais simples ainda têm seus usos, e se tornou ainda mais simples realizá-los — geralmente com plataformas dedicadas a isso e até com IA.
E os web scraping mais complexos, como os feitos dentro do ambiente das redes sociais, abre um verdadeiro guarda-chuva de possibilidades para executivos e gestores de marketing sagazes o suficiente para fazer as perguntas certas.
Hoje, a tecnologia do web scraping chegou a um ponto onde não precisamos mais pensar se é possível. Precisamos pensar na finalidade do scraping.
Possível é. Existem métodos diferentes para canais e finalidades diferentes.
Separamos aqui os principais tipos de web scraping que você pode colocar em prática hoje. E trazemos um mini-tutorial em cada um, com ferramentas, plataformas e, quando ficar muito complicado, o que a equipe técnica pode fazer.
Depois, para fechar o texto, vamos trazer um tutorial mais detalhado de como fazer web scraping dentro das redes sociais, para finalidades diferentes.
Acompanhe:
Redes sociais
É possível coletar dados públicos de perfis: nome, bio, número de seguidores, número de contas seguidas, volume de publicações, frequência de postagem, engajamento médio, hashtags utilizadas e interações visíveis.
O objetivo pode variar:
- Mapear influenciadores;
- Identificar padrões de crescimento;
- Monitorar concorrentes;
- Construir bases para análise de audiência;
Também é possível ir além da coleta direta. Com modelagem estatística, é viável estimar probabilidade de perfil ser bot, detectar padrões artificiais de engajamento e classificar tipos de criadores.
Mas isso é assunto para o final do texto, onde trazemos um tutorial avançado de web scraping em redes sociais.
Como fazer via plataformas
Existem plataformas especializadas que já entregam parte dessas informações estruturadas, como:
Essas soluções permitem configurar extração de dados públicos sem necessidade de programação avançada. São indicadas quando o objetivo é rapidez e menor dependência técnica interna.
O problema é que elas são pagas: a mais barata começa em US$ 69 dólares mensais, no plano mais simples.
Como fazer via script próprio
A equipe técnica pode:
- Mapear as requisições de rede feitas pela plataforma;
- Identificar endpoints que retornam dados estruturados;
- Replicar as requisições via Python (requests);
- Armazenar em banco de dados;
- Criar métricas derivadas (ex: razão follower/following, frequência de postagem).
Caso o conteúdo exija renderização dinâmica, pode ser necessário automação de navegador com ferramentas como Playwright.
Vamos conversar sobre essa ação em detalhes no último tópico do texto!
Conteúdo de sites institucionais (palavras-chave)
É totalmente possível extrair todos os textos públicos de um site e identificar:
- Palavras mais recorrentes;
- Termos estratégicos;
- Padrões de discurso;
- Frequência temática.
O objetivo é inteligência de conteúdo: entender posicionamento, SEO, narrativa institucional ou mapear lacunas.
Como fazer via plataformas
Ferramentas de crawling e análise textual como:
Permitem extrair URLs, textos e até gerar relatórios de palavras-chave automaticamente.
Como fazer via script próprio
A equipe técnica pode:
- Criar crawler para percorrer todas as URLs internas;
- Extrair conteúdo textual;
- Limpar HTML;
- Processar o corpus com bibliotecas de NLP;
- Calcular frequência ou TF-IDF.
Aqui o scraping é simples. O diferencial está na análise posterior.
Porém, ferramentas de SEO como SemRush e Ahrefs já fazem esse trabalho, e é bastante provável que sua equipe de conteúdo ou já tenha uma dessas ferramentas ou precise delas.
Criar um crawler do zero leva tempo e é difícil justificar esse tempo para a diretoria. Ao mesmo tempo, as plataformas podem ser utilizadas para outras funcionalidades.
No próximo item, vamos conversar sobre uma situação onde criar esse script faz até mais sentido.
Veja:
Conteúdo de e-commerce (lista de produtos por categoria)
É possível extrair:
- Nome do produto;
- Preço;
- SKU;
- Categoria;
- Disponibilidade;
- Avaliação.
O objetivo costuma ser monitoramento competitivo, análise de sortimento e mapeamento de catálogo.
Como fazer via plataformas
Use ferramentas como:
- ThunderBit (antigo ParseHub);
- Octoparse.
Permitem configurar extração por categoria, inclusive com paginação automática.
Como fazer via script próprio
A equipe pode:
- Identificar padrão de URL por categoria;
- Mapear paginação;
- Extrair dados estruturados do HTML ou da API interna;
- Armazenar em banco relacional;
- Agendar atualização periódica.
O ponto crítico aqui não é apenas coletar a lista de produtos, mas estruturar o processo como rotina permanente.
Um e-commerce é dinâmico: preços mudam, produtos saem de linha, novas categorias surgem, estoques oscilam.
Se o script não estiver preparado para lidar com exceções — como páginas vazias, redirecionamentos ou mudanças de layout — ele quebra silenciosamente e compromete a base inteira.
Por isso, a equipe técnica deve prever:
- Tratamento de erros e logs detalhados;
- Validação automática de dados coletados;
- Identificação de duplicidades;
- Versionamento ou histórico quando necessário.
Quando bem implementado, o scraping deixa de ser uma extração pontual e passa a ser uma camada contínua de inteligência competitiva. O script vira infraestrutura de dados
Monitoramento de preços ao longo do tempo
Além de capturar preços atuais, é possível:
- Acompanhar variações diárias;
- Detectar promoções;
- Identificar ruptura de estoque;
- Mapear sazonalidade;
O objetivo é inteligência competitiva e precificação estratégica.
Como fazer via plataformas
Algumas plataformas especializadas já oferecem monitoramento contínuo de preços, como:
Elas automatizam coleta e alertas.
Como fazer via script próprio
A equipe pode:
- Criar rotina de scraping agendada;
- Armazenar histórico de preços;
- Construir tabela temporal;
- Gerar alertas internos quando houver variação relevante;
Aqui o diferencial não é coletar uma vez, mas manter a base atualizada continuamente.
Mapeamento de reputação e avaliações
O que é possível fazer e qual é o objetivo
É possível coletar:
- Notas médias;
- Comentários de usuários;
- Volume de avaliações;
- Datas de publicação.
O objetivo é análise de sentimento, identificação de problemas recorrentes e comparação com concorrentes.
Como fazer via plataformas
Plataformas de monitoramento de reputação e reviews como:
Podem centralizar menções e comentários públicos. Inclusive, temos um texto muito interessante sobre o assunto publicado aqui no blog, com foco em social listening + IA.
Acesse logo abaixo:
➡️O que é e como começar a fazer social listening
Como fazer via script próprio
A equipe técnica pode:
- Extrair avaliações por produto ou perfil;
- Processar texto com análise de sentimento;
- Classificar comentários por tema;
- Construir relatórios comparativos
Como fazer scraping + modelagem de dados em redes sociais

Um ponto que precisamos conversar antes de fechar o texto é sobre a necessidade de modelar os dados extraídos para trazer mais utilidade aos dados.
Ao invés de trabalharmos com informações cruas, a modelagem de dados permite a criação de regras que fazem uma análise dos dados obtidos, com base na estatística, e entrega probabilidades reais sobre as características dos dados.
Por exemplo: você ganha 500 seguidores por mês na sua marca. Como saber qual é a porcentagem desses seguidores que realmente se interessa pelo seu conteúdo?
Ou você quer informações mais aprofundadas sobre seu público, como por exemplo a faixa etária. Como saber, com base nas informações possíveis de extrair com o scraping? Lembrando que a maioria das pessoas não preenche a idade no perfil.
Isso tudo acontece através da modelagem de dados. Vamos entender agora, em um passo a passo simples, como fazer o scraping, como criar a modelagem e como entregar tudo isso em um formato acessível para todos.
Acompanhe:
Passo 1 — Definir a pergunta estratégica
Antes de qualquer linha de código, é preciso definir o que se quer descobrir.
Exemplos:
- Qual percentual dos novos seguidores realmente interage?
- Qual a probabilidade de um perfil ser bot?
- Qual a faixa etária predominante estimada da audiência?
- Qual o nível médio de afinidade com o tema da marca?
É à partir dessa pergunta fundamental que você vai tanto encontrar a melhor forma de fazer o scraping como criar a modelagem de dados.
Passo 2 — Mapear quais dados públicos permitem responder essa pergunta
Nem tudo é extraível. E quase nada é explícito. A resposta da pergunta estratégica muitas vezes vai vir por inferência. A modelagem de dados, um pouco mais pra frente, vai entregar resultados de acordo com essas inferências iniciais.
Em geral, é possível coletar:
- Username;
- Bio;
- Número de seguidores;
- Número de contas seguidas;
- Volume de posts;
- Frequência de publicação;
- Curtidas e comentários visíveis;
- Hashtags utilizadas;
- Data aproximada de criação da conta (quando inferível).
Esses são dados brutos. Sozinhos, dizem pouco. Vamos conversar sobre como fazer o scraping abaixo, e depois, sobre como extrair inferências através da modelagem de dados.
Passo 3 — Construir o scraper
Como conversamos, você pode usar plataformas para fazer esse trabalho de uma forma mais simples.
Ferramentas como Apify ou Phantombuster permitem coletar dados públicos de perfis e exportar em CSV ou integrar com planilhas.
É o caminho mais rápido para validar hipóteses, mas também acaba sendo o menos personalizável.
As plataformas permitem o scraping com foco em informações diferentes, mas você pode querer outras que elas não permitem analisar.
Via script próprio esse problema não existe, mas o trabalho é mais longo e técnico:
- Mapear requisições feitas pela rede social;
- Identificar endpoints que retornam dados estruturados;
- Replicar chamadas via Python;
- Armazenar os dados em banco (SQL ou similar);
- Garantir tratamento de erros e controle de bloqueios
Aqui termina o scraping. A partir daqui começa a inteligência.
Passo 4 — Estruturar a base para modelagem
Antes de modelar, é necessário organizar. Algumas ações essenciais precisam ser tomadas para limpar e clusterizar seus dados.
É preciso:
- Normalizar dados;
- Remover duplicidades;
- Padronizar formatos;
- Criar colunas derivadas.
Isso pode ser feito através de planilhas, manualmente, ou através de scripts pontuais que operam dentro do banco de dados.
Exemplo de colunas derivadas:
- Razão follower/following;
- Engajamento médio por post;
- Frequência mensal de publicação;
- Crescimento estimado.
Essas variáveis são insumos para inferência. Aqui, você é quem vai decidir quais são as derivações dos dados que você está coletando. Essa é a modelagem de dados na prática.
Passo 5 — Criar regras estatísticas simples (modelagem inicial)
Modelagem não precisa começar complexa. Você pode começar com algumas lógicas bem simples. Veja alguns exemplos:
Exemplo 1 — Probabilidade de bot
Regras combinadas:
- Segue 5.000 contas e tem 50 seguidores;
- Posta 10 vezes por dia;
- Bio genérica ou ausente;
- Engajamento extremamente baixo.
Cada critério recebe um peso. A soma gera um score de probabilidade.
Exemplo 2 — Interesse real no conteúdo
Se a marca ganha 500 seguidores por mês, é possível cruzar:
- Seguidores novos;
- Engajamento desses seguidores nos 30 dias seguintes;
- Interações recorrentes.
Assim, cria-se uma taxa de “seguidor ativo” versus “seguidor passivo”.
Exemplo 3 — Estimativa de faixa etária
Não se extrai idade diretamente. Mas é possível inferir por:
- Linguagem utilizada na bio;
- Emojis recorrentes;
- Referências culturais;
- Tipo de conteúdo compartilhado.
Com base em amostras conhecidas, cria-se um modelo probabilístico.
Perceba como a lógica é inteiramente sua.
Uma vez determinada a forma com que a modelagem é feita (geralmente por script), é necessário ter pessoas de estratégia e especialistas em marketing para fechar quais são as análises que serão conduzidas e quais os dados determinantes para essa análise.
Ou seja: o difícil nem é tanto construir o script. Você vai precisar de bastante criatividade para criar as regras de captura do script.
Passo 6 — Evoluir para modelagem mais robusta
Com volume suficiente de dados, a equipe pode aplicar:
- Classificação supervisionada;
- Clustering;
- Análise de similaridade;
- Modelos preditivos simples.
Aqui o scraping deixa de ser coleta e passa a alimentar um sistema analítico. A ferramenta escolhida para a função vai entregar dados para um sistema. Ele vira uma verdadeira dashboard.
Passo 7 — Transformar dados em decisão
Nenhum executivo quer planilha bruta. O resultado final deve ser:
- Dashboard simples;
- Percentuais claros;
- Scores interpretáveis;
- Alertas automáticos
Exemplo de saída executiva:
- 38% dos novos seguidores apresentam baixo potencial de engajamento;
- 12% têm alta probabilidade de comportamento automatizado;
- Faixa etária predominante estimada: 18–24 anos (probabilidade 64%).
É assim que funciona a modelagem de dados junto com o web scraping.
Hoje, a forma mais comum com que o trabalho se apresenta é essa, via redes sociais e aplicando algum tipo de modelagem de dados para ter inspirações mais aprofundadas sobre o que estamos encontrando.
Um ponto que esse texto não tratou mas que é muito importante é sobre o monitoramento de IAs.
Não é possível fazer scraping de IA, mas é totalmente possível analisar sua performance dentro dela.
Criamos um guia nesse mesmo estilo para essa funcionalidade. Acesse logo abaixo:
➡️ Análise de performance em IA: como fazer SOV + 3 plataformas


Posts recentes
Nosso blog tem conteúdos semanais feitos por especialistas

3 níveis de relacionamento contínuo no marketing

Como limpar uma base de leads? Guia para 5 plataformas de marketing

Growth com inteligência artificial: 3 guias de governança
Torne seu marketing digital mais estratégico
Agende uma conversa e receba o contato da nossa equipe. Temos um time de especialistas em desenvolver soluções e entregar resultados.
